
Database normalization is beneficial for retailers that rely on inventory files to change their online inventory. Without it, an inventory file can quickly become unmanageable, leading to errors in the listing process.
But what exactly is database normalization and why is it important? Today, we’re explaining database normalization for the Amazon merchant who wants to manage their inventory better.
And if you’re wondering how technical you need to be for database normalization, don’t worry – we break it down in easy-to-understand terms.
What is database normalization and why is it important?
Databases help retailers organize and store information about products and customers. However, it can be challenging to work with when a product database has too many redundancies or improper organization.
Because of how vital business data is, it’s necessary to have a way to keep it tidy and consistent. That’s where database normalization comes in.
Database normalization involves making sure that a database organization structure is efficient. Removing redundancies and accurately storing data makes a normalized database easier to work with and less likely to contain errors.
There are three main benefits of database normalization:
- Increased data accuracy.
- Reduced overhead costs for your business.
- More manageable inventory lists and order forms.
Companies and small businesses sometimes maintain product databases by themselves or rely on third-party services to keep and normalize their product information.
There are many different types of databases, but most databases have some common characteristics. They also provide some fantastic benefits to retailers.
A normalized database shows relationships between your products, inventory files, and customers in an easy-to-read and understandable way.
While it may not seem like a big deal at first glance, normalization can make all the difference in inventory management, data analysis, and even product pricing.
The different forms of database normalization
The most common forms of database normalization are known as the first, second, and third normal forms.
Although there are several other levels of normalization, these are the most well-known and used in general databases.
These forms of database normalization involve breaking down complex data into smaller pieces.
By understanding the levels of normalization and the benefits associated with each, you can ensure that your product database is optimized for maximum efficiency.
Although it may seem like a lot of work at first, database normalization can be relatively easy to implement once you get the hang of it.
First Normal Form (1NF)
The First Normal Form (1NF) is the most basic form of database normalization. To be in this form, a database must meet the following criteria:
- You must store all data in a single table.
- There can be no repeating groups of data.
- All columns must have a single primary key.
1NF is a set of rules for designing databases that ensures they’re easy to understand and update.
The goal is for every table to have one and only one key column. In addition, each row should contain all the information it needs to identify itself uniquely.
So essentially, if you’re sure only to have one table per entity type, you’ve already fulfilled 1NF.
Second Normal Form (2NF):
The Second Normal Form (2NF) is a bit more complex. To be in this form, a database must meet the following criteria:
- The database must first be in 1NF.
- No non-key column can depend on any other non-key column for its meaning or existence.
- All columns must have a single primary key.
2NF reduces redundancy and ensures that data is accessible in the most efficient way possible. By breaking down complex data into smaller pieces, it’s easier to understand and update the database.
In 2NF, each non-key attribute should depend only on its key attribute. For example, if we had a table called Customer_Orders, which contained information about customers and orders, the customer ID would be the key attribute.
The customer ID is the key attribute because it uniquely identifies each customer. The other attributes in the table, such as the customer’s name, address, and phone number, depend on the customer ID.
Alternatively, the order number would be a non-key attribute because it depends on the customer ID.
To add a new order to this table, first select the customer ID from the table. Then, insert the new order into the table using the customer ID as the row identifier.
This organizational structure is essential for optimizing data management, analysis, and reporting. And it’s one of the main reasons retailers choose to implement database normalization.
Third Normal Form (3NF):
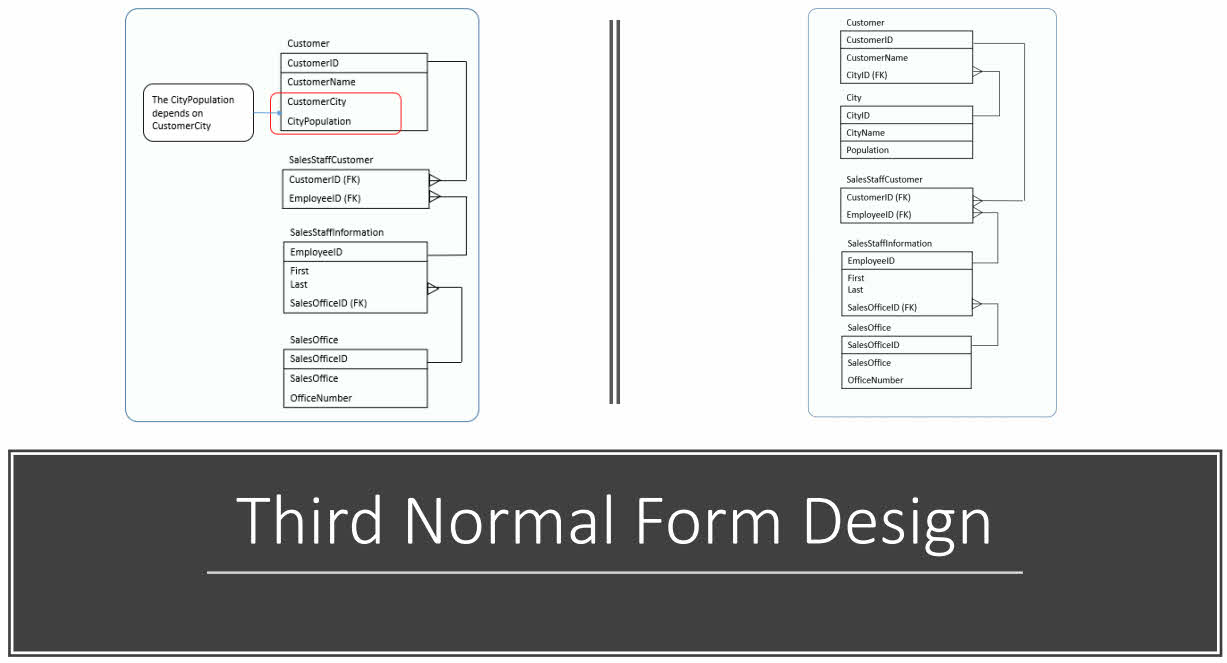
The Third Normal Form (3NF) is a set of rules which define what constitutes a valid relational database design. These rules ensure that all tables used in a database are appropriately normalized.
The 3NF is the most complex form of database normalization. To be in this form, a database must meet the following criteria:
- The database must first be in 2NF.
- No non-key column can depend on any other non-key column that has not already been included as part of its key.
- All columns must have a single, primary key.
The 3NF reduces redundancy further and ensures that databases are efficient and scalable.
It’s essential to achieve 3NF to optimize your database design for maximum data efficiency and processing speed.
This structure will help optimize data management and reporting. Still, it also helps ensure that your data is accurate and up-to-date.
What about Boyce-Codd Normal Form?
There’s a variation of the 3NF called the Boyce-Codd normal form (BCNF). This variation works with database tables with multiple candidate keys.
To be in BCNF, a database table must meet the following criteria:
- The database must first be in a 3NF.
- No non-key column can depend on any other non-key column that is not part of its candidate key.
- Each candidate key must have a single, non-NULL value in each row.
Overall, database normalization aims to reduce redundancies and improve data integrity while maintaining optimal performance and organization. Understanding these different forms of normalization is essential for designing an effective database.
So if you’re working with an extensive database, it’s crucial to ensure that your data is normalized correctly to optimize performance and maximize efficiency.
And with the right tools and techniques, this process can be quick and painless, so here are 5 tips for maintaining a normalized database.
5 tips for maintaining a normalized database
Normalizing a database takes time and effort, which is why some retail brands prefer to avoid it altogether. However, the benefits of a normalized database far outweigh the costs.
1) Build out your raw database to conform to a normal form
Taking a raw product database and conforming it to a specific normal form is not easy, but with the right tools and techniques, your brand can do it relatively quickly and easily.
A few steps that will help you with the process include:
- Defining the entity and its attributes.
- Identifying the primary keys.
- Reducing redundancies using 1NF, 2NF, and 3NF techniques.
Follow this process to reduce the time and effort required to maintain your normalized database.
2) Aim for referential integrity
One of the most important goals of database normalization is to achieve referential integrity. Referential integrity means that all data in your database is consistent, accurate, and up-to-date.
There are a few steps you can take to help ensure referential integrity in your normalized database, including:
- Defining primary and foreign keys.
- Establishing relationships between tables.
- Enforcing data integrity rules.
Without referential integrity, your data can quickly become outdated and inaccurate. So take the time to build out and manage your normalized database to maintain referential integrity.
3) Search for any deletion anomalies & update anomalies
This step can be tricky, but it’s crucial if you want to maintain your normalized database. Deletion anomalies occur when deleted data has a reference elsewhere in the database.
To prevent deletion anomalies, it’s crucial to search for any records affected by deletion and update the related records accordingly.
Update anomalies involve updated data in one place but not updated in other referencing records.
These anomalies are relatively common. Yet, you can easily avoid them by taking the time to search for and update relevant records before making any significant database changes.
4) Consider your company’s needs while creating a database design
When creating a database for stores, keep your company’s needs in mind. For example, focusing on performance and scalability will be crucial if you work with an extensive database.
On the other hand, security is likely your top priority if you’re dealing with sensitive customer data.
Either way, consider your company’s specific needs and build your database design accordingly. While building a product database, ask yourself how the final design will benefit your company and its customers.
5) Look out for any dependency that could break normalization rules
This one can be difficult to maneuver, but it’s essential to watch for any dependencies that could break normalization rules. These dependencies can quickly break your normalized database if you’re not careful. So be sure to keep an eye out for any potential problems and take steps to resolve them as quickly as possible.
There are a few different types of dependencies that can break normalization rules, including:
Transitive dependencies
A transitive dependency occurs when two attributes are functionally dependent on a third attribute. For example, if you have an address table with the attributes street, city, and state, the city attribute is transitively dependent on the state attribute.
Partial dependencies
A partial dependency occurs when a non-prime attribute is functionally dependent on only a part of a composite primary key. For example, if you have an employee table with the attributes employee ID, last name, and first name, the first name attribute is partially dependent on the (employee ID, last name) composite primary key.
Functional dependencies
A functional dependency occurs when one attribute is functionally dependent on another, such as a street being functionally dependent on the city.
Amazon and normalized product data
Amazon requires your product data for your listings to either be manually entered or uploaded using a flat file. A normalized database can ensure that your data is consistent, accurate, and up-to-date, for flat file uploads. However, it doesn’t guarantee that the data will be free of errors specific to Amazon.
Emplicit’s SaaS product FlatFilePro is our proprietary Amazon listing software which synchronizes inventory data directly to Amazon Seller Central via our API. It enables you to identify errors before you upload your data, makes the process a breeze, and back-ups your product data in the required form. Discover more about FlatFilePro.
