
LSTM models are transforming how ecommerce businesses predict demand. By analyzing time-series data, these models help reduce overstocking, avoid stockouts, and improve operational efficiency. Unlike older methods like ARIMA, LSTMs excel at handling fluctuating sales patterns, seasonal trends, and promotional events.
Key takeaways:
- Improved Accuracy: LSTMs reduce forecast errors significantly, with studies showing a 15% improvement in Mean Absolute Percentage Error (MAPE) compared to traditional methods.
- Advanced Features: Variants like Bidirectional LSTMs and attention mechanisms refine predictions further.
- Multivariate Inputs: Including factors like promotions, holidays, and customer behavior enhances forecasting.
- Real-World Success: Walmart.com and other retailers have achieved better inventory planning and cost savings using these models.
Whether you’re managing daily sales spikes or seasonal demand, LSTMs offer a reliable, data-driven solution for ecommerce forecasting.
How LSTM Models Work for Demand Prediction
LSTM Architecture Overview
At the heart of every LSTM model is a memory cell that determines what information to retain, update, or discard as it processes sequences of data. This design helps solve the vanishing gradient problem. In traditional RNNs, signals from earlier data points weaken as they propagate backward during training, making it difficult for the model to learn from long-term patterns. LSTMs, however, use "constant error carousels" to maintain stable signals across extended sequences.
"LSTMs address the long-term dependency problem by incorporating a sophisticated gating mechanism. This allows them to selectively remember or forget information, effectively transmitting relevant information through long time series." – Chenyang Wang, Marine Engineering College, Dalian Maritime University
This architecture is what makes LSTMs particularly effective at handling the unpredictable nature of ecommerce demand.
Applications in Ecommerce
LSTM models are especially well-suited for managing the complexities of ecommerce demand, which often fluctuates unpredictably. Ecommerce sales data is inherently dynamic – demand can surge overnight due to flash sales, plummet after holidays, or shift gradually with seasonal trends. LSTM models are designed to handle this type of non-linear demand variability.
An example highlights their strength: researchers analyzing 350 product categories during the 2024 Mathorcup Big Data Competition observed dramatic demand changes. For instance, "Category 61" experienced a jump from 1,939 units to 3,693 units on July 21, followed by peaks of 4,236 units in August and 3,987 units in September. The LSTM model accurately captured these sharp shifts, enabling precise replenishment planning for specific dates – something linear models like ARIMA struggle to achieve.
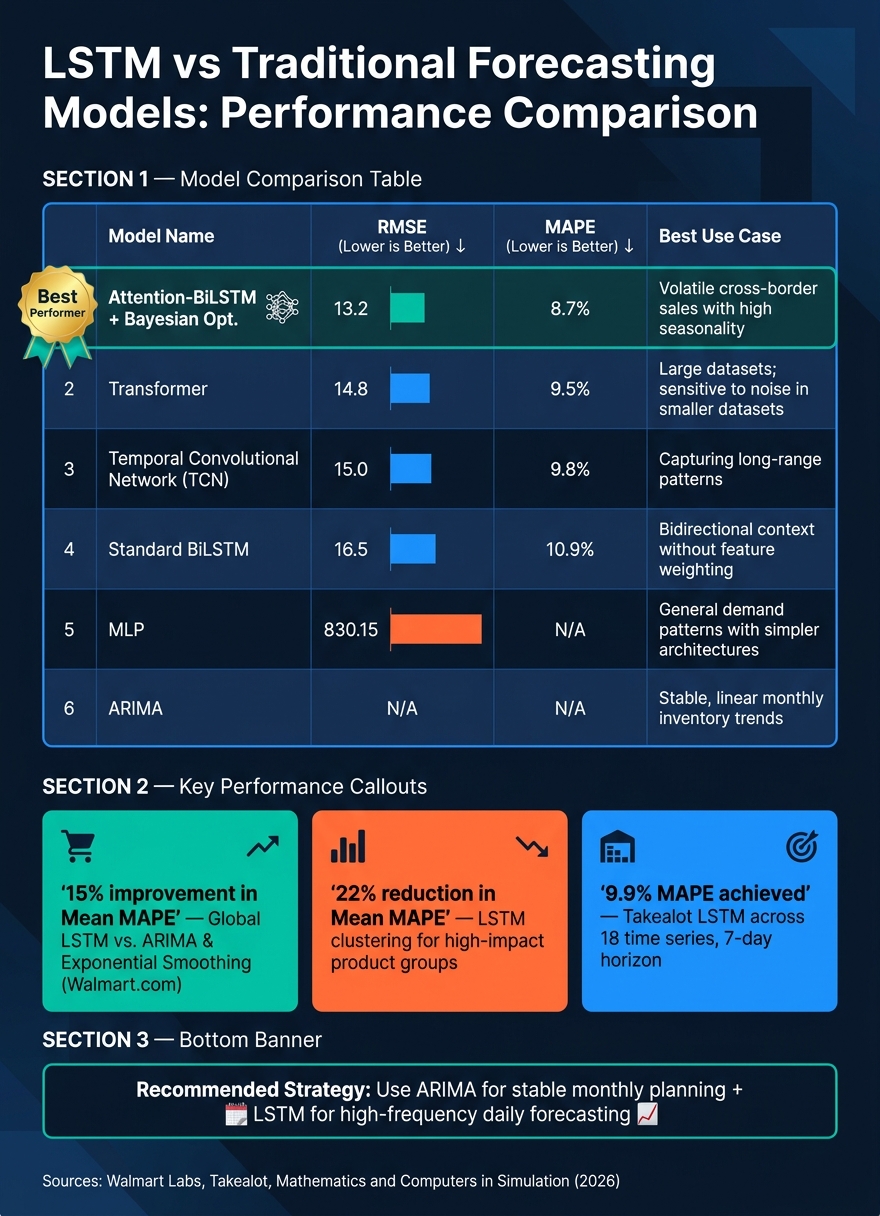
Advanced versions of LSTMs, such as Bidirectional LSTMs (BiLSTM) combined with an attention mechanism, take this a step further. These models can pinpoint key time steps, such as promotional events or holiday weekends, to refine predictions. For example, a Bayesian-optimized attention-BiLSTM applied to cross-border ecommerce data achieved a MAPE of 8.7% and an R-squared value of 0.92, outperforming standard BiLSTM models (RMSE: 16.5) and even Transformer-based models (RMSE: 14.8).
Input Data and Time Series Structures
The success of LSTM models also depends on the quality and variety of input data. Using only sales history limits forecasting accuracy. Instead, LSTMs thrive on multivariate inputs, incorporating data like promotion schedules, holiday markers, customer activity, and delivery times. This additional context enables the model to distinguish a regular Tuesday from one during a major sale.
A common approach to structuring data is the sliding window method. For example, a 30-day window uses the past 30 days of data to predict the next day’s demand. This setup allows the model to continuously adapt to recent trends without losing sight of broader seasonal patterns. Additionally, for products with correlated demand – such as complementary items or products within the same category – integrating cross-series information from product hierarchies can further enhance accuracy. Research from Walmart.com, conducted by Monash University and Walmart Labs, demonstrated the effectiveness of this approach.
LSTM Time Series Forecasting with TensorFlow & Python – Step-by-Step Tutorial
Research Findings: LSTM Performance in Ecommerce
LSTM vs Traditional Forecasting Models: Performance Comparison
Key Research Results
Recent studies highlight the strength of LSTM models in handling the dynamic nature of ecommerce forecasting. For instance, in one study, LSTM achieved an RMSE of 811.81, outperforming Multilayer Perceptron (MLP) models, which recorded an RMSE of 830.15. While the numerical difference may seem minor, the impact becomes significant when forecasting thousands of SKUs daily.
"Memory-based models such as LSTM are more effective for highly volatile time-series forecasting in e-commerce operations." – Ica Unari, STMIK IKMI Cirebon
A real-world example comes from Walmart.com. Using 190 days of sales data, a globally trained LSTM outperformed traditional methods like ARIMA and exponential smoothing by 15% in Mean MAPE. Additionally, applying specialized LSTM clustering strategies reduced Mean MAPE by 22% for high-impact product groups.
Interestingly, forecast error (measured by WMAPE) rises by about 11.3% for every unit increase in the Demand Complexity Index (DCI). This finding underscores the challenges even advanced models face when demand patterns grow more erratic.
Advanced LSTM Variants
Enhanced versions of LSTM models offer even better accuracy. For example, Bidirectional LSTMs (BiLSTM) process data in both forward and backward directions, enabling them to better capture dependencies. When paired with an attention mechanism, these models can focus on critical trends, seasonal patterns, or promotional events.
A January 2026 study in Mathematics and Computers in Simulation examined an Attention-Enhanced BiLSTM optimized through Bayesian techniques for cross-border ecommerce data. The results were impressive: RMSE of 13.2, MAPE of 8.7%, and an R² of 0.92. This performance surpassed standard BiLSTM (RMSE: 16.5, MAPE: 10.9%) and even Transformer-based models (RMSE: 14.8, MAPE: 9.5%).
"BiLSTM captures both forward and backward dependencies, offering deeper insights into sales patterns." – Hao Hu, Researcher, Zhejiang Polytechnic University
Another variant, ConvLSTM, incorporates convolutional operations into LSTM state transitions. A study using JD.com sales data (January 2016–December 2017) across 1,000 products showed that ConvLSTM, combined with Horizontal Federated Learning, not only improved forecasting accuracy but also maintained data privacy at the warehouse level. This approach also mitigated the bullwhip effect across the supply chain. By addressing both accuracy and privacy, ConvLSTM proves its value in complex ecommerce environments.
Comparing Forecasting Methods
No single model fits all scenarios. The best choice depends on factors like data size, demand variability, and specific goals. Here’s how different methods stack up:
| Method | RMSE | MAPE | Best Use Case |
|---|---|---|---|
| Attention-BiLSTM + Bayesian Opt. | 13.2 | 8.7% | Volatile cross-border sales with high seasonality |
| Transformer | 14.8 | 9.5% | Large datasets; sensitive to noise in smaller datasets |
| Temporal Convolutional Network (TCN) | 15.0 | 9.8% | Capturing long-range patterns |
| Standard BiLSTM | 16.5 | 10.9% | Scenarios needing bidirectional context without feature weighting |
| MLP | 830.15 | N/A | General demand patterns with simpler architectures |
| ARIMA | N/A | N/A | Stable, linear monthly inventory trends |
The research suggests a dual-model strategy: using ARIMA for stable, monthly inventory planning and LSTM models for high-frequency, daily sales forecasting. This combination allows each model to play to its strengths, ensuring more accurate predictions tailored to different demand scenarios.
sbb-itb-e2944f4
Implementing LSTM Models in Ecommerce
Feature Engineering for Better Predictions
The quality of input data plays a huge role in the success of LSTM models. Combining static attributes like product category and brand with dynamic signals such as price changes, promotions, seasonal trends, and even weather patterns creates a more robust feature set. Beyond sales history, behavioral data – like page views, add-to-cart actions, and wishlist activity – can further improve the accuracy of forecasts.
One often-overlooked step in preprocessing is addressing "fake" zeros. For example, when a product is out of stock, sales data may show zeros, but that doesn’t reflect actual demand. Replacing these zeros with missing values before training prevents the model from learning misleading patterns.
Scaling the target variable is another critical step. Takealot‘s engineering team discovered in April 2025 that their TiDE models struggled to converge when trained on raw sales data in the 100,000-unit range. By normalizing these figures to single-digit values, they resolved the issue entirely.
"LSTMs are still powerful for short forecast horizons, with a limited lookback window." – Izak Marais, Machine Learning Engineer, Takealot
Once features are refined, the focus shifts to configuring the training process to make the most of these improvements.
Training and Evaluating the Model
LSTMs excel at capturing long-term dependencies, but their performance relies on an effective training strategy. For ecommerce forecasting, using a 30-day sliding window to create time-series sequences allows the model to learn temporal patterns. Fine-tuning hyperparameters – such as window size, the number of LSTM layers, and the learning rate – can significantly improve forecast accuracy.
When it comes to evaluation, walk-forward validation is the go-to method for time-series models. Unlike standard cross-validation, it respects the chronological order of the data, ensuring the model is only tested on future periods it hasn’t seen. This approach prevents data leakage and provides a realistic measure of performance.
For reference, Takealot’s LSTM system, which forecasted daily unit sales across 18 time series over a 7-day horizon, achieved a MAPE of 9.9% – a strong result in the high-SKU ecommerce world.
Scaling and Deploying LSTM Models
Once the model is trained and validated, scaling it for real-world use becomes the next challenge. Training separate models for each SKU isn’t practical at scale. Instead, a global LSTM – trained on related product time series simultaneously – can capture cross-series correlations, often outperforming individual univariate models. Walmart.com saw a 15% improvement in Mean MAPE using this approach compared to traditional methods.
To further enhance accuracy, group similar SKUs based on factors like warehouse location, lead time, or sales volume. Takealot, for instance, used six distinct groupings to achieve their 9.9% MAPE.
Finally, automating re-training is essential to keep forecasts up-to-date. Tools like Kubernetes cronjobs can handle this process efficiently. By implementing these strategies, ecommerce businesses can improve demand forecasting and streamline inventory management.
Conclusion: Key Takeaways and Next Steps
Key Takeaways for Ecommerce Businesses
LSTM models offer a powerful upgrade over older forecasting methods, especially in the unpredictable world of ecommerce. Unlike traditional approaches like ARIMA, which struggle with irregular patterns, LSTMs excel at managing fluctuations – whether it’s daily sales spikes, promotional events, or seasonal trends. When applied across product hierarchies, they also uncover connections between related SKUs. For example, research using Walmart.com data showed a 15% improvement in Mean MAPE, and when products were grouped into clusters, that number jumped to 22% for high-impact categories. These advancements translate to real-world benefits: better forecasting accuracy can lower backorder rates by up to 30% and trim inventory costs for storage and transportation by 5% to 10%. As research evolves, LSTM models continue to improve, offering even more precise solutions for ecommerce challenges.
Future Research Directions
The future of LSTM models in ecommerce forecasting lies in areas like attention mechanisms, meta-learning, and Explainable AI (XAI). Quantum-inspired Attention LSTM models, for instance, have reached forecasting accuracies as high as 92.85% on ecommerce datasets. Meta-learning models, such as Meta-LLSTM, tackle the tricky cold-start problem for new product launches, achieving an RMSE that’s 16.97% lower than standard RNNs. Meanwhile, XAI tools like ShapTime and Permutation Feature Importance aim to make LSTM predictions easier to interpret.
"Although deep learning techniques have advanced, the lack of interpretable models hampers understanding and explaining predictions." – Evolutionary Intelligence, Springer Nature
How Emplicit Can Help

Turning these LSTM advancements into actionable business strategies requires more than just technical know-how – it demands clean data, organized product catalogs, and a clear plan to act on forecasts. Emplicit specializes in helping ecommerce businesses bridge this gap. Their services – ranging from inventory management to listing optimization and PPC management – enable companies to leverage better demand forecasts for smarter stock management and stronger marketplace performance on platforms like Amazon, Walmart, and TikTok Shops.
FAQs
What data do I need to train an LSTM for demand forecasting?
To get an LSTM model ready for ecommerce demand forecasting, you’ll need a dataset with multiple dimensions. The essential inputs include historical sales figures, pricing information, promotion details, holiday markers, and external influences like weather conditions or market trends.
Start by preparing your data: clean it to remove errors or inconsistencies, scale the values to ensure uniformity, and convert any categorical variables into one-hot-encoded vectors. Finally, organize the data into fixed-length sequences. This structure helps the model better recognize and learn from temporal patterns over time.
How do I handle out-of-stock days (zero sales) in LSTM training data?
When dealing with out-of-stock days (resulting in zero sales), it’s essential to recognize that these periods don’t necessarily represent actual consumer demand. To handle this, techniques like pastcasting – for example, using tools such as Pastprop-LSTM – can help reconstruct disrupted sales data during training. Another approach involves using adaptive inventory correction modules, which adjust for anomalies caused by stock issues. These strategies prevent the model from wrongly interpreting zero sales as a lack of customer interest.
Should I use one global LSTM or separate models for each SKU?
When deciding between a global LSTM model or separate models, it largely hinges on your product data and sales trends. A global model works well when there are shared patterns across multiple SKUs, as it can tap into cross-series insights. On the other hand, if sales behaviors differ widely, it might be more practical to group similar SKUs and train individual models for each group. Emplicit specializes in refining forecasting strategies to drive growth on major ecommerce platforms and marketplaces.